Hamming Query Expansion
One of the most successful techniques in information retrieval is the query expansion (QE) principle, which is a kind of automatic relevance feedback. The general idea is to exploit the reliable results returned by an initial query to produce an enriched representation, which is re-submitted in turn to the search engine. Query expansion has been introduced to the visual domain by Chum et al. and several extensions have been proposed to improve this initial QE scheme. Although these variants have improved the accuracy, they suffer from two inherent drawbacks which severely affect the overall complexity and quality of the search. First, they all require a costly geometrical verification step. Second, the augmented query representation contains significantly more non-zero components than the original one, which severely slows down the search.

Query image (left) and the features selected (yellow+cyan) from the retrieved images to refine the original query. The features in red are discarded. Cyan features correspond to visual words that appear in the query image, and yellow ones to visual words that were not present in it. The selection of the depicted images and features has not involved any geometrical information.
Our baseline system consists of the Hamming Embedding technique with burstiness normalization and multiple assignement of visual words to the query features. A simple rule based on the number of correspondences formed with a strict threshold on the hamming distance is used to detect reliable images. These are exploited to form an enhanced query representation. As shown in the example below, this simple rule is sufficient to correctly detect true relevant images as reliable images (green border).

The most frequent visual words which appear among reliable images are identified as the most useful ones for the expanded query. Features mapped to those visual words are called reliable features. Their binary signatures are aggregated per visual word in order to form a more compact representation which is finally proven to further be more robust.

Sample reliable images and features assigned to reliable visual words, when geometry is not used. Left: Query image. Right: Features of database images assigned to reliable visual words that appear in the query image. Note: we only show a subsample of the actual reliable visual words. Each color represents a distinct visual word.
Our method is shown to be effective even without the use of geometry verification in contrast to previous query expansion methods. However, combined with spatial matching performance is further increased as shown in our experiments.

Features selected for the expanded set of a particular query image (left) without (middle) and with spatial matching (right). With spatial matching: features back-projected out of the bounding box are rejected (red), while the rest (blue and green) are kept. Those assigned to reliable visual words are shown in green. Without spatial matching: features assigned to reliable visual words are shown in cyan or yellow, with yellow being the ones assigned specifically to augmentation visual words. Rejected are shown in red.
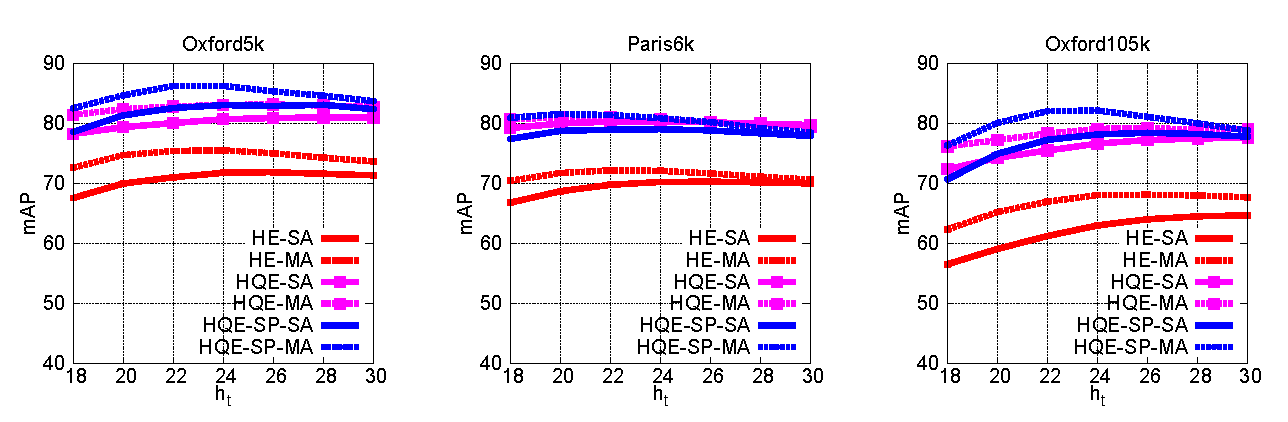
We evaluate the proposed method on two publicly available datasets of this kind, namely Oxford5k Buildings and Paris, but also on a dataset where queries have only few corresponding images, that is UKB. Our method Hamming Query Expansion (HQE) is shown to always improve the performance of the baseline retrieval system based on Hamming Embedding (HE). When combined with geometry (HQE-SP) the performance is further improved.
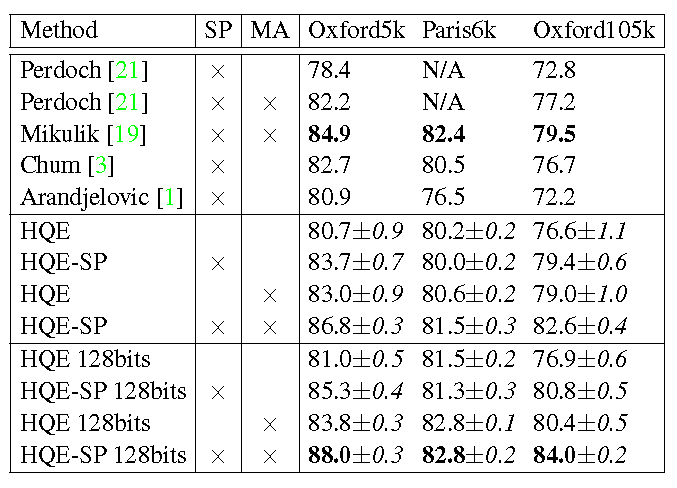
We compare the QE proposed method with previously published results on the same datasets. For a fair comparison, we have included the scores of other QE methods that have used the same local feature detector as input and learned the vocabulary on an independent dataset. We also include the scores for our method when using 128-bit signatures for HE, which are better at the cost of higher memory usage and a slightly larger complexity. Interestingly, even without spatial matching, our method outperforms all methods in Oxford105k and Paris6k dataset. HQE-SP outperforms them in all three datasets. All of the compared methods rely on spatial matching to verify similar images and expand the initial query.