Although human vision appears to be easy and unconscious there exist complex neural mechanisms in primary visual cortex that form the preattentive component of the Human Visual System (HVS) and lead to visual awareness. Considerable research has been carried out into the attention mechanisms of the HVS and computational models have been developed and employed to common computer vision problems. Most of the models simulate the bottom-up mechanism of the HVS and their major goal is to filter out redundant visual information and detect/enhance the most salient parts of the input. The Human Visual System has the ability to fixate quickly on the most informative (salient) regions of a scene and reduce therefore the inherent visual uncertainty. Computational visual attention (VA) schemes have been proposed to account for this important characteristic of the HVS. We study and expand the field of computational visual attention methods, propose novel models both for spatial (images) and spatiotemporal (video sequences) analysis and evaluate both qualitatively and quantitavely in a variety of relevant applications.
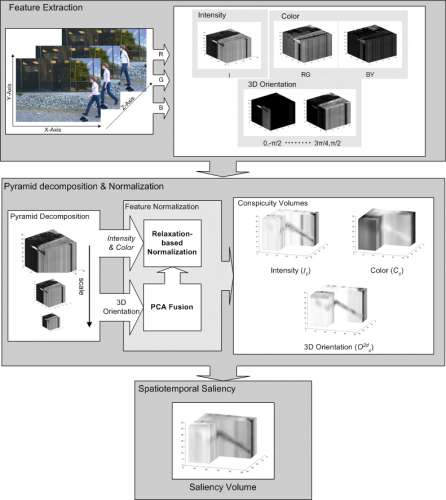
Many computer vision applications often need to process only a representative part of the visual input rather than the whole image/sequence. Considerable research has been carried out into salient region selection methods based either on models emulating human attention mechanisms or on more computational plausible solutions of vision. Most of the proposed methods are bottom-up and their major goal is to filter out redundant visual information and detect/enhance the most salient one. In this paper, we propose and elaborate on a saliency detection model that treats a video sequence as a spatiotemporal volume and generates a local saliency measure for each visual unit (voxel). This computation involves an optimization procedure incorporating inter- and intra- feature competition at the voxel level. Perceptual decomposition of the input, spatiotemporal center-surround interactions and the integration of heterogeneous feature conspicuity values are described and an experimental framework for video classification is set up. This framework consists of a series of experiments that shows the effect of saliency in classification performance and how well the salient regions represent the visual input. A comparison of the proposed method against other is attempted that shows the potential of the proposed method.