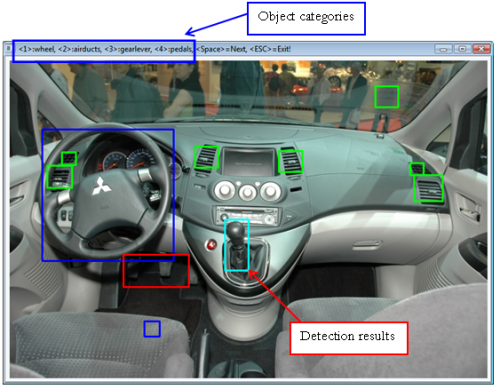
Annotator is an image annotation tool that supports both manual and semi-automatic annotation. It opens and displays images from a folder and displays the proposed bounding boxes for each object category to annotate. The user can edit (resize, move or change object category) or delete the existing bounding boxes and add new ones. When the annotation of the current images is completed, Annotator continues with the next image.
The user interface of Annotator is very simple. Each object category corresponds to one key in the keyboard. The least physical effort is required by the user, since one hand controls the mouse for creating and editing the bounding boxes, and the other hand is placed on the left side of the keyboard, having most frequently used operations at these keys. Finally, only a few seconds are needed to annotate objects in one image.
Ease of use and speed of the overall annotation task were the main objectives when creating this tool. The GUI is very simple in order to boost annotation speed. That way, the user can annotate easily large sets of images, in order to acquire large training and testing image sets.
In order to annotate images in a semi-automatic way, Annotator initially "guesses" the bounding boxes for each object category. The user can edit and delete those bounding boxes. Also, the number of the automatically detected results can change, by adapting a threshold for the detection proccess.
Annotator was written in C++ using the OpenCV library. OpenCV was used for opening and displaying images, object detection and user input handling.
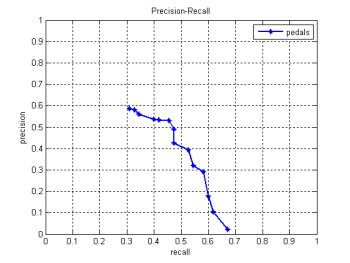
In order to work in semi-automatic mode, the user has to provide object detectors created with OpenCV. These object detectors are based on the Viola & Jones detection method [ViJo01]. Each object category detector is saved in a xml file. We include four detectors in the download package (object categories are from the interior of cars - steering wheel, airduct, gear lever and pedals).
In order to create a detector for a new object category, the user has to provide a training set of images. This set of images must be annotated for the particular object category, by hand. The training set with its annotation will be given to the detector training program, which will create the detector. Using this detector, the user can easily annotate the test set of images in semi-automatic mode. Then, this set can be used to evaluate the created detector.
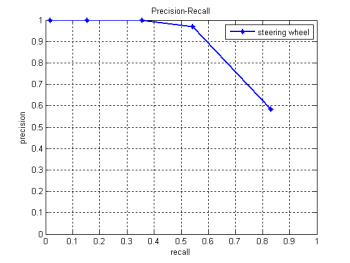
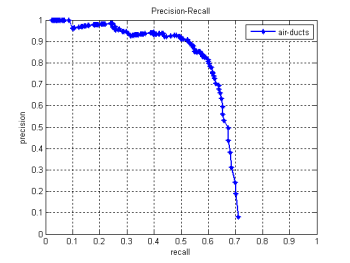
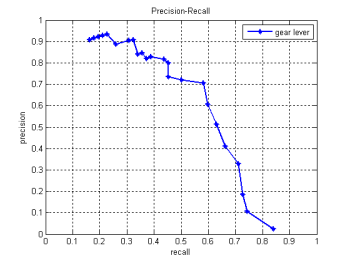
The following graphs show the performance of the detectors we created for steering wheels, air-ducts, gear levers and pedals. The training set we used, consisted of 700 images, and the test set of 80 images, all depicting the interior of cars.
 |
 |
 |
 |
Documentation (pdf, 272.35 KB)
Executable (2.1 MB)
Christos Varytimidis
e-mail: chrisvar@image.ntua.gr