Automatic segmentation of images and videos is a very challenging task in computer vision and one of the most crucial steps toward image and video understanding. In this research work we propose to include semantic criteria in the segmentation process to capture the semantic properties of objects that visual features such as color or texture are not able to describe. Traditionally, the tasks of segmentation and recognition have been treated sequentially and inevitably erroneous segmentation leads to poor results in recognition while imperfections of global image classification are responsible for deficient segmentation. It is rather obvious that limitations of one prohibit the efficient operation of the other. We propose an algorithm that involves simultaneous segmentation and recognition of objects, based on region growing techniques, where region merging is based on semantic similarity criteria.
- An image or a video sequence is decomposed into a set of non-overlapping regions or volumes, respectively. Each region/volume is assigned a fuzzy set of semantic labels such as: \[ \mathcal{L}_{a}=\sum_{i=1}^{|C|}{c_i/\mu_{a}(c_i)} \] where $\mathcal{L}_{a}$ is the fuzzy set of labels for region/volume $a$. $C$ is the set of all possible concepts, $\mu_{a}(c_{i})$ is the degree of membership of the concept $c_{i}$ in the fuzzy set $\mathcal{L}_{a}$.
- A semantic similarity measure between two neighbour regions/volumes $a$ and $b$ is defined, based on their fuzzy sets of semantic labels $\mathcal{L}_{a}$ and $\mathcal{L}_{b}$: \[ s_{ab}=\max_{c_{i}\in{C}}\langle T_{norm}(\mathcal{L}_{a},\mathcal{L}_{b})\rangle \] where $T_{norm}$ can be any fuzzy t-norm. Intuitively, semantic similarity $s_{ab}$ is the highest degree, implied by our knowledge, that regions/volumes $a$ and $b$ share the same concept.
- An Attributed Relational Graph (ARG) is used as representation of an image or video sequence. Graph's vertices represent regions/volumes with their assigned fuzzy sets as attributes, while graph's edges correspond to semantic similarity between the connected vertices (regions/volumes).
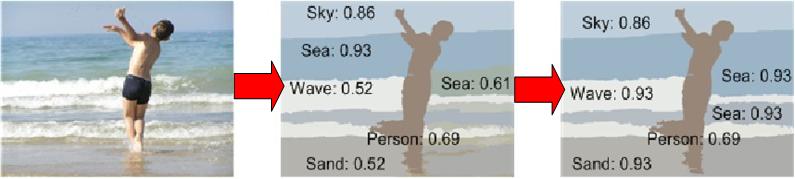
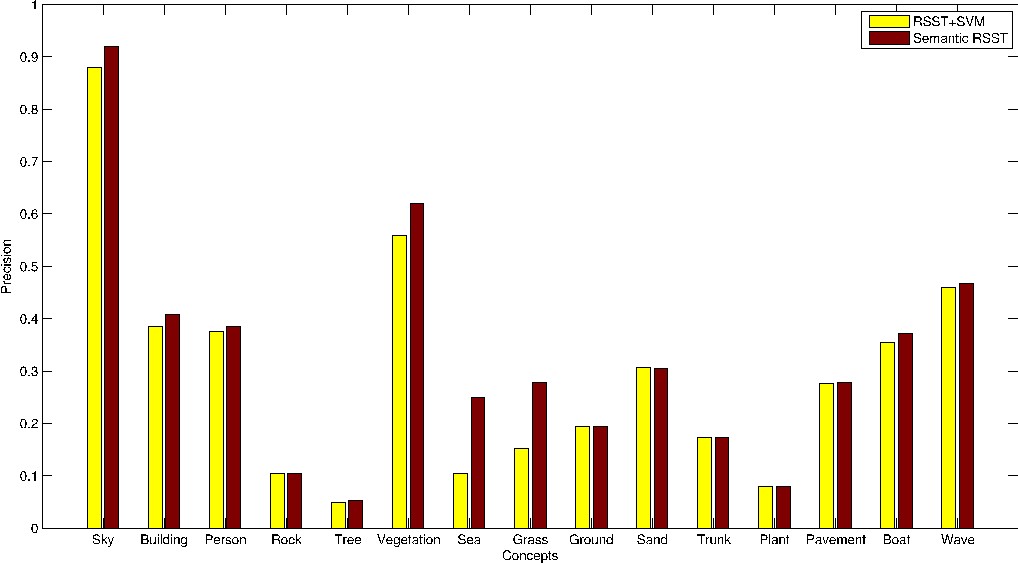
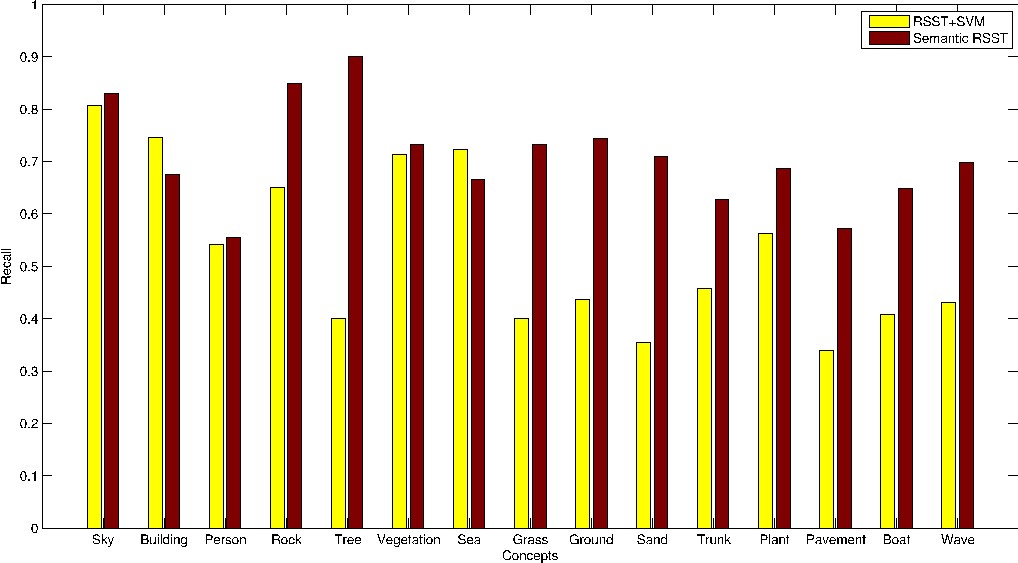
The figure below illustrates the recognition results using as input a standard hierarchical segmentation algorithm, such as RSST (second column), while the third column displays the results of the proposed semantic segmentation algorithm. One can notice the improvement in oversegmented areas like the wavy sea or shadowed parts of the sand, while at the same time the confidence of recognition also increased.

In the case of video sequences, our goal is to successfully match spatiotemporally segmented volumes within and between blocks of frames (BoFs), in order to achieve a consistent and semantically meaningfull video segmentation. One can see the difference between consecutive BoFs of the second and the third collumn, where in the latter the consistent color index indicates correct tracking of objects. Segmentation of these objects (person, sea and sky) is illustrated in the last three collumns respectively.

 |
 |