The goal of this tool is to demonstrate the integration of several low- to high-level analysis algorithms toward semantic indexing of images. Different modules created by several research groups have been included and results are presented graphically in a unified way.
In more detail, the algorithms that are integrated in this tool are:
- Image segmentation: Modified RSST
- Segmentation refinement: Semantic Region Growing based on concurrent segmentation and detection
- Feature extraction: MPEG-7 Visual Descriptors Extraction
- Classification: SVM and bio-inspired approaches
- Classifier fusion: Fusion of the above classifiers based on Evidence Theory
- Fuzzy reasoning: Extraction of implicit knowledge based on Fuzzy Reasoning Engine FiRE
- Knowledge base: Storing analysis results to Sesame via COMM ontology
- Retrieval: Semantic queries to Sesame knowledge base
 |
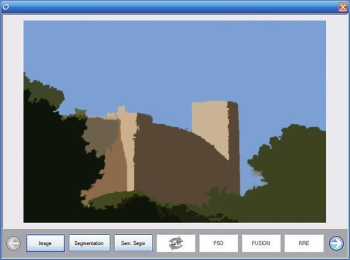 |
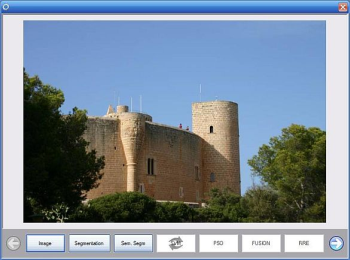
The greater part of the demo window is occupied by the processed image, while the different steps (modules) have dedicated buttons below the image. All modules run sequentially and the results are displayed once each module has completed its execution. Above, the result of the semantic segmentation module is illustrated.
 |
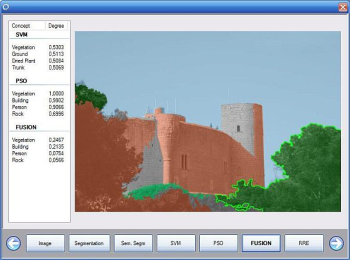 |
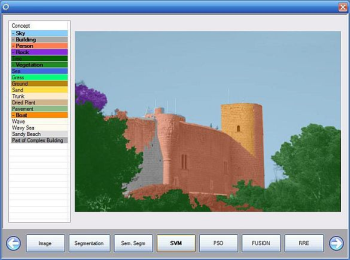
The tool allows the user to see the different concepts that were detected on the processed image, and overlays each concept on the original image with a predefined color, to make it easier to the user to observe changes in between modules. In addition, if the user clicks on the image, the four concepts with the higher degree of confidence, will be shown, along with their degrees, for both the selected module and all previously run modules. This ensures that the tool cannot be used for demo purposes only, but can be used as a quick comparison between two or more different algorithms for the same task.
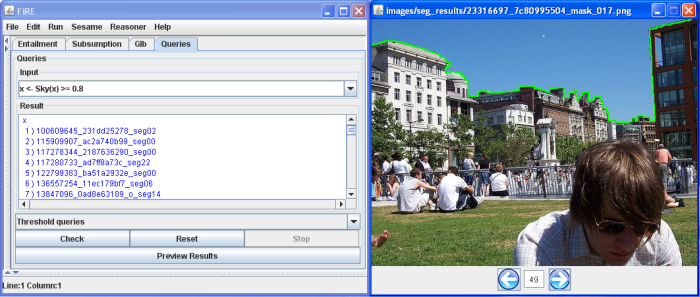
The user interface for posing a semantic query to the knowledge-base is illustrated above. The retrieved images are displayed at the right, with highlighted the region that matched the query, e.g. images with sky regions with degree of confidence above 80%. Other more complex (but closer to human-style) queries might be like "bring me images with people at a beach".
 |
 |
 |
 |
| (a) | (b) | (c) | (d) |
 |
 |
 |
 |
| (e) | (f) | (g) | (h) |
Above we can see the first 8 retrieved images for the query "beach and person". In addition, at the table below we illustrate the ranking of the images, based on the degrees of the intermediate concepts that compose the conjuctive query "beach and person".
| Image | Sea | Sky | Beach | Person | Total |
| (g) | 0.90 | 0.87 | 0.87 | 0.86 | 0.87 |
| (b) | 0.83 | 0.91 | 0.83 | 0.80 | 0.80 |
| (d) | 0.69 | 0.66 | 0.66 | 0.81 | 0.66 |
| (f) | 0.63 | 0.47 | 0.47 | 0.85 | 0.63 |
| (h) | 0.60 | 0.83 | 0.60 | 0.85 | 0.60 |
| (a) | 0.47 | 0.92 | 0.47 | 0.84 | 0.47 |
| (c) | 0.46 | 0.91 | 0.46 | 0.86 | 0.47 |
| (e) | 0.44 | 0.73 | 0.44 | 0.83 | 0.44 |
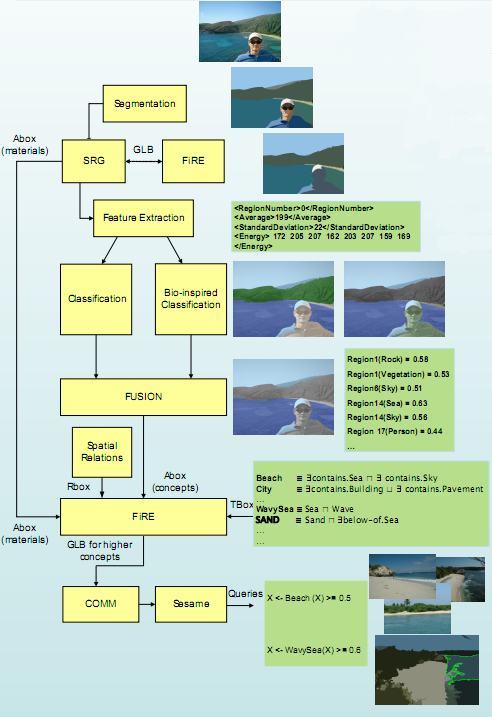
In the picture below the overall architecture is illustrated. In the process-flow exist three levels of semantic information:
- no semantics: segmentation based on low-level features
- mid-level semantics: segmentation refinement based on object detection, region-based classification
- rich semantics: fuzzy reasoning for extraction of implicit knowledge, storing in and retrieving from a knowledge-base
finik@image.ntua.gr