Using a Visual Dictionary for High-Level Concept Detection
The motivation of this work is to tackle the problem of high-level concept detection within image and video documents using a globally annotated training set. The goal is to determine whether a concept exists within an image along with a degree of confidence and not its actual position. Since this approach begins with a coarse image segmentation, the high-level concepts that is able to tackle can be described as "materials" or "scenes". MPEG-7 color and texture features are locally extracted from coarsely segmented regions using an RSST variation. Using a significantly large set of images and after the application of a hierarchical clustering algorithm on all regions, a relatively small number of them, is selected. These regions are called "region types". This set of region types composes a visual dictionary which facilitates the mapping of low- to high-level features.
The process of calculating a model vector using a visual dictionary and some examples of model vectors.
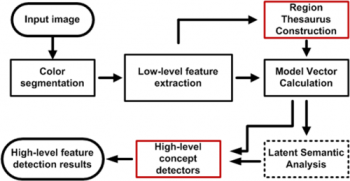
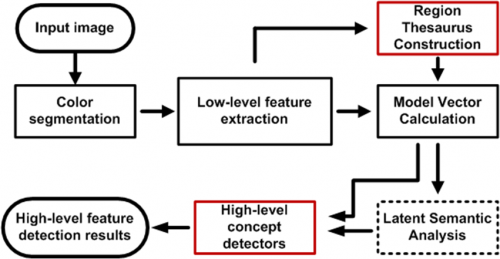
A flowchart depicting the overall classification process. By red, the offline parts are depicted, while the dotted box depicts the LSA which is an optional part of the process.
A "model vector" is finally extracted to represent the visual properties in terms of the region types it contains. This model vector representation is then used to train SVM-based concept detectors. To further improve the performance of this algorithm, the Latent Semantic Analysis technique is applied to exploit the hidden relations among region types.
Results
This approach is thoroughly tested on a small dataset of images and for a set of concepts that derive from the natural disaster domain and also in the large dataset of the TRECVID 2007 development data.
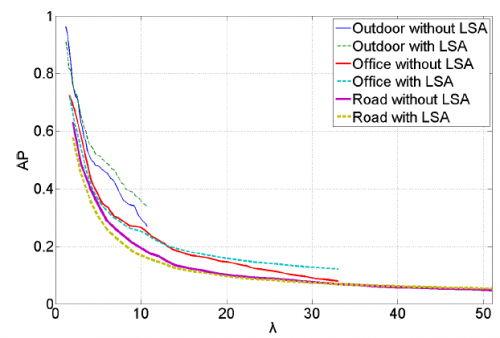
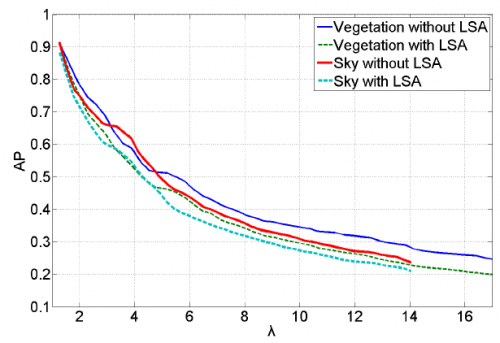
Average Precision of the proposed approach vs the ratio λ of negative to positive examples of the test set, with and without LSA.
For certain concepts such as Outdoor, Office and Road, LSA improves the results, while λ increases. This means that positive examples are detected in a lower and more correct rank. The common thing among these concepts is that they cannot be described in a straightforward way, such as Vegetation and Sky.
| Concept |
Number of
positives
|
λ=4 |
λ=max |
| Before LSA |
After LSA |
Before LSA |
After LSA |
| P |
R |
AP |
P |
R |
AP |
P |
R |
AP |
P |
R |
AP |
| Vegetation |
1939 |
0.643 |
0.312 |
0.460 |
0.626 |
0.221 |
0.395 |
0.322 |
0.313 |
0.232 |
0.268 |
0.222 |
0.179 |
| Road |
923 |
0.295 |
0.046 |
0.280 |
0.400 |
0.050 |
0.210 |
0.045 |
0.047 |
0.043 |
0.036 |
0.051 |
0.044 |
| ExplosionFire |
29 |
0.291 |
0.777 |
0.182 |
0.200 |
0.111 |
0.148 |
0.000 |
0.000 |
0.001 |
0.001 |
0.111 |
0.000 |
| Sky |
2146 |
0.571 |
0.304 |
0.436 |
0.559 |
0.271 |
0.372 |
0.258 |
0.304 |
0.214 |
0.288 |
0.207 |
0.184 |
| Snow |
112 |
0.777 |
0.411 |
0.460 |
0.818 |
0.264 |
0.529 |
0.013 |
0.412 |
0.008 |
0.023 |
0.265 |
0.012 |
| Office |
1419 |
0.446 |
0.157 |
0.318 |
0.406 |
0.147 |
0.285 |
0.117 |
0.157 |
0.072 |
0.095 |
0.148 |
0.110 |
| Desert |
52 |
0.333 |
0.312 |
0.287 |
0.215 |
0.687 |
0.246 |
0.003 |
0.313 |
0.064 |
0.001 |
0.438 |
0.063 |
| Outdoor |
5185 |
0.425 |
0.514 |
0.361 |
0.331 |
0.634 |
0.382 |
0.683 |
0.510 |
0.515 |
0.601 |
0.646 |
0.522 |
| Mountain
|
97 |
0.444 |
0.137 |
0.241 |
0.110 |
0.035 |
0.072 |
0.003 |
0.379 |
0.037 |
0.003 |
0.172 |
0.001 |
Extensive results for the cases of λ=4 and λ=max.
This approach has also been applied as part of the joint COST292 and K-Space submissions to the high-level feature extraction task of TRECVID 2006 and 2007.